
从端到端3D重建到可查询4D世界
连续两年,CVPR的最佳论文都在回答同一个问题:能否让一个统一的前向 (feed-forward) 视觉模型,直接从图像或视频中建立场景的几何世界表示,并一次性解决相机、深度、点云/点迹这些原本分散的3D/4D任务?
去年的最佳论文VGGT给出的答案是:3D可以端到端。它把相机内外参、深度、点云、点迹放进同一个Transformer里,上百张图一次前向推理就能出结果——摒弃了传统SfM/MVS流程中的精雕细琢的几何计算模块。
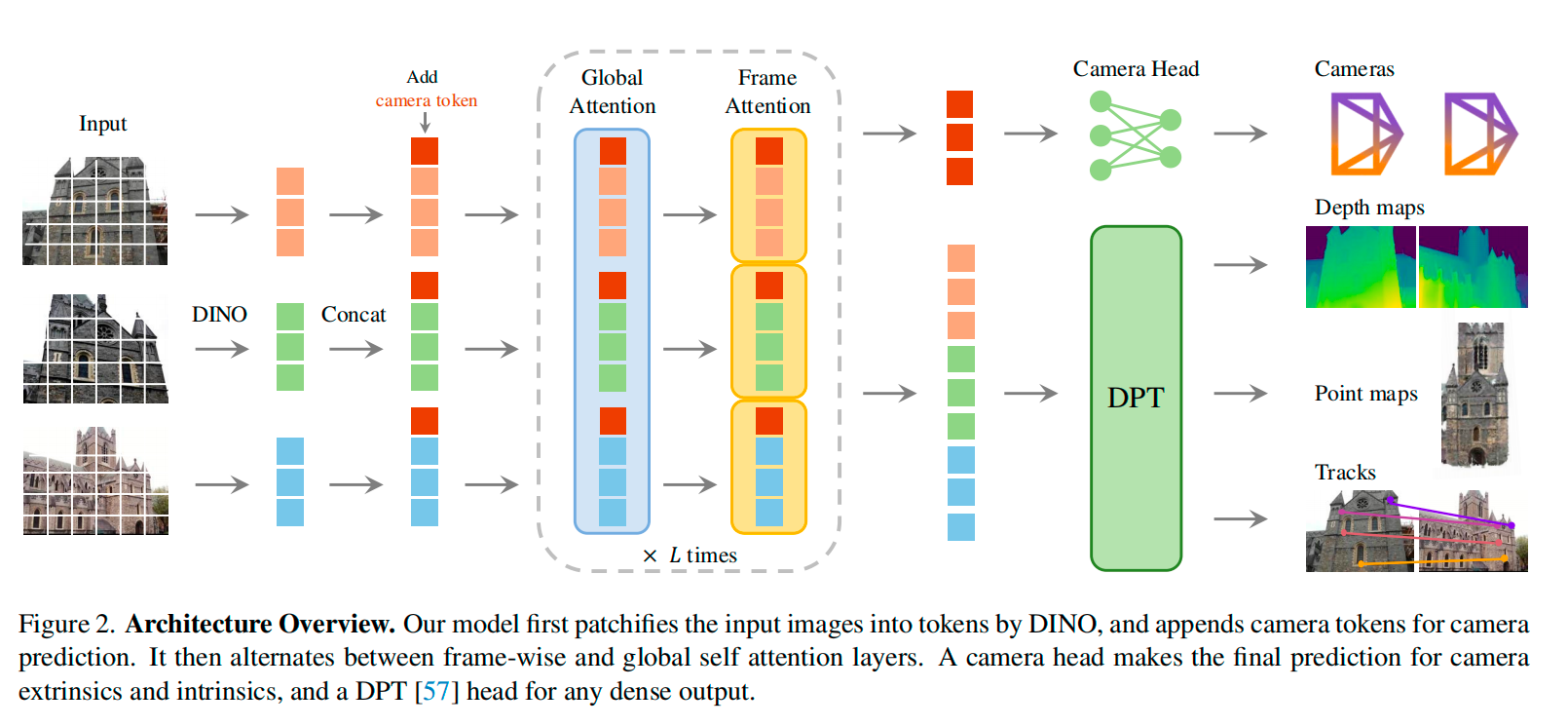
今年的最佳论文D4RT更进一步,不局限于静态多视图,而是输入动态视频。把要解决的建立几何世界的问题转换成了:给定视频里任意一帧的任意某个像素,如何知道这个点在任意时刻、任意参考相机坐标系下的3D位置?
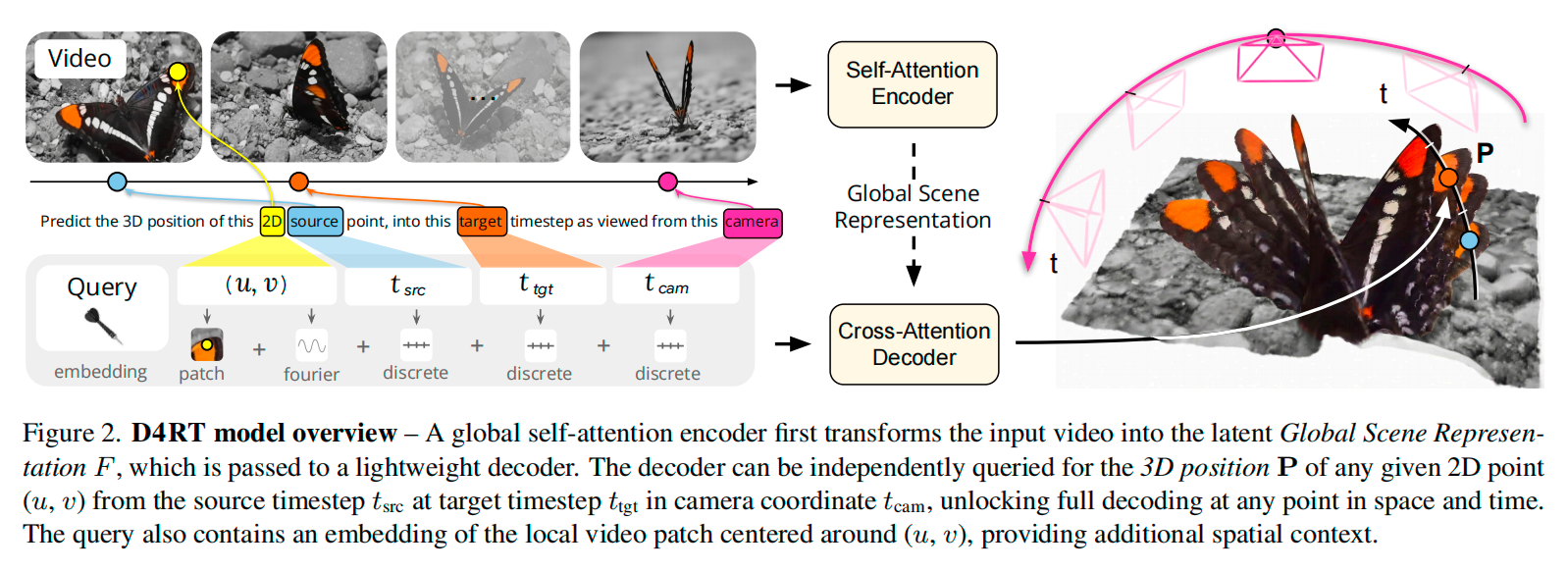
D4RT重要的不仅是达到了SOTA,更是把范式从稍难接受的“万物端到端”,改成了“完整表征+轻量查询”:先用Encoder把整段视频编码成一个Global Scene Representation,再用Decoder去问(Query)—— 这个像素在视频流第10帧、以第5帧相机为参考系的位置是什么?
具体来说,D4RT把任务统一成一个Query token (私以为最巧妙的地方)。这个Query token 里包含五类信息:像素在源帧里的归一化2D坐标、源帧时间步、目标时间步、参考相机,以及这个像素周围9×9 RGB patch的embedding。然后Decoder拿这个Query token去cross-attend全局场景表征,最终输出一个3D点。
颇有几分类似LLM统一接口的意味:先将世界压缩为一个整体表征,再根据需求进行查询。也许未来真正有价值的3D/4D模型,不再只是输出一片漂亮的点云,而是能回答“物体在哪里、从哪来、会去哪”的空间、时间与运动问题。
也许这是3D领域的LLM时刻?