
From End-to-End 3D Reconstruction to a Queryable 4D World
For two consecutive years, the CVPR Best Paper has been answering the same question: Can a unified feed-forward vision model directly build a geometric world representation of a scene from images or videos, and solve, in one shot, the originally fragmented 3D/4D tasks such as camera estimation, depth prediction, point cloud reconstruction, and point tracking?
Last year’s Best Paper, VGGT, gave the answer for 3D: it can be done end-to-end. VGGT puts camera intrinsics and extrinsics, depth, point clouds, and point tracks into the same Transformer. With a single forward pass, it can process up to hundreds of images and produce the results directly, largely bypassing the carefully engineered geometric computation modules in traditional SfM/MVS pipelines.
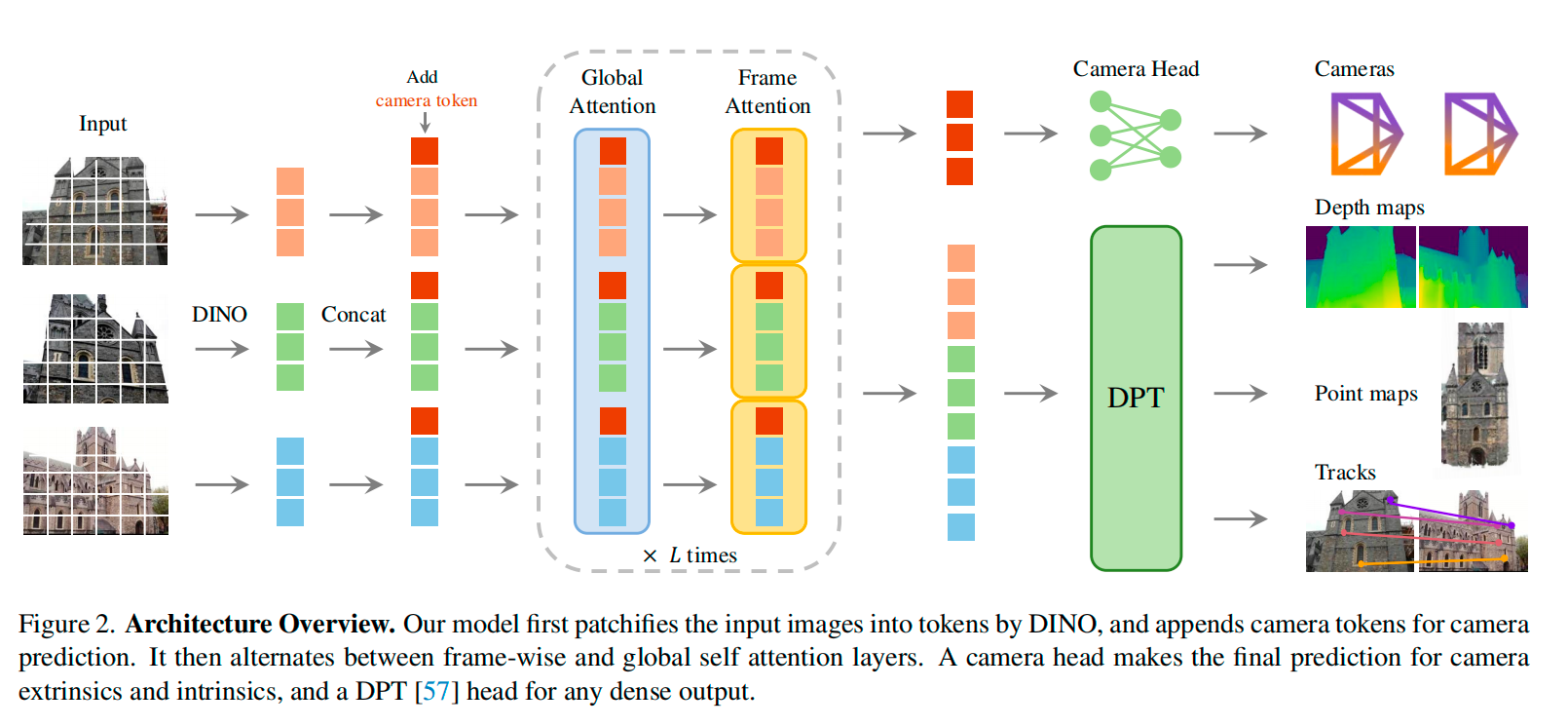
This year’s Best Paper, D4RT, goes one step further. It is no longer limited to static multi-view images, but takes dynamic videos as input. It reformulates the problem of building a geometric world representation into the following question: given any pixel in any frame of a video, how can we determine the 3D position of that point at any moment in time and under any reference camera coordinate system?
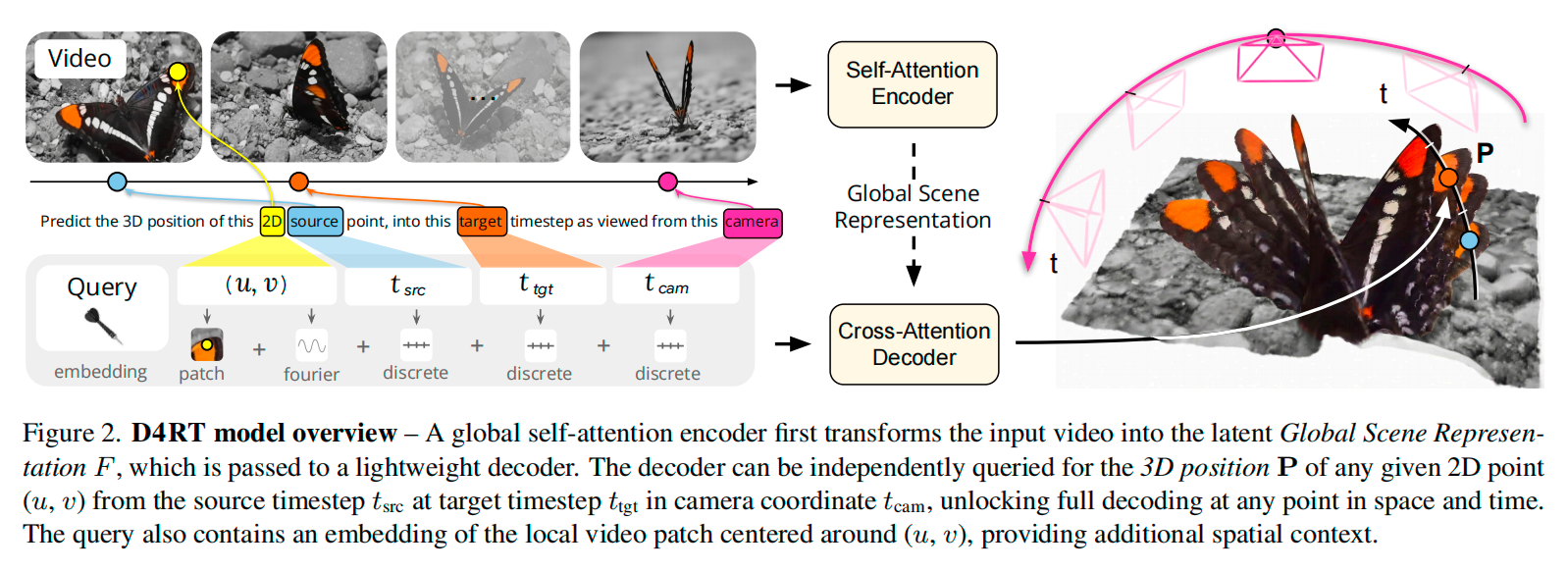
What makes D4RT important is not only that it achieves SOTA performance, but that it shifts the paradigm from the somewhat harder-to-accept idea of “end-to-end everything” to “complete representation + lightweight query.” First, an Encoder compresses the entire video into a Global Scene Representation. Then, a Decoder asks queries such as: Where is this pixel in frame 10? If we use the camera of frame 5 as the reference, how should the point cloud of the whole video be aligned?
More specifically, D4RT unifies the task into a single Query token, which I think is its most elegant design. This Query token contains five types of information: the normalized 2D coordinate of the pixel in the source frame, the source-frame timestep, the target timestep, the reference camera, and the embedding of the 9×9 RGB patch around that pixel. The Decoder then uses this Query token to cross-attend to the global scene representation and finally outputs a 3D point.
This has a flavor similar to the unified interface of LLMs: first compress the world into a holistic representation, then query it as needed. Perhaps the truly valuable 3D/4D models of the future will not merely output a beautiful point cloud, but answer questions about space, time, and motion: Where is the object? Where did it come from? Where will it go? Maybe this is the LLM moment for 3D vision.